Reading Time: 11 minutesIntroduction
Machine Learning (ML) and Artificial Intelligence (AI) are not new concepts, you may have heard these buzz words thrown around and mentioned on various products or services. These concepts can help solve real world problems in a unique and optimal way. Object detection is one challenge that can be tackled with Machine Learning that can evolve and become more accurate over time. Azure Cognitive Services provides developers the capability to tap into this technology to easily develop solutions for challenges in our daily lives. Azure also offers an image recognition service called Custom Vision. This blog post will explain the fundamentals of ML and walk you through how easy it can be to create your own object detection system using Custom Vision. Utilizing this tool can unlock a treasure trove of use cases applicable to you or your business.
What is Machine Learning?
Machine learning, put simply is a branch of Artificial Intelligence (AI) that focuses on mimicking human behaviour by observing data and using algorithms to learn and improve itself gradually over time. This is the process of learning that we all naturally do. We observe experiences looking for patterns to help direct us into making better decisions. The ultimate goal for a computer is to be able to learn, improve and adjust its actions according to its experiences without any human intervention or assistance.
Building an Object Detection System with Custom Vision
In this demonstration we will build an object detection system to recognise vehicle number plates in images. You may have come across a system that does this already such as the entrance and exit boom gates at a shopping centre or a police patrol vehicle parked on the highway. They both utilise a technology known as Automatic Number Plate Recognition (ANPR) which uses ML algorithms to accomplish this.
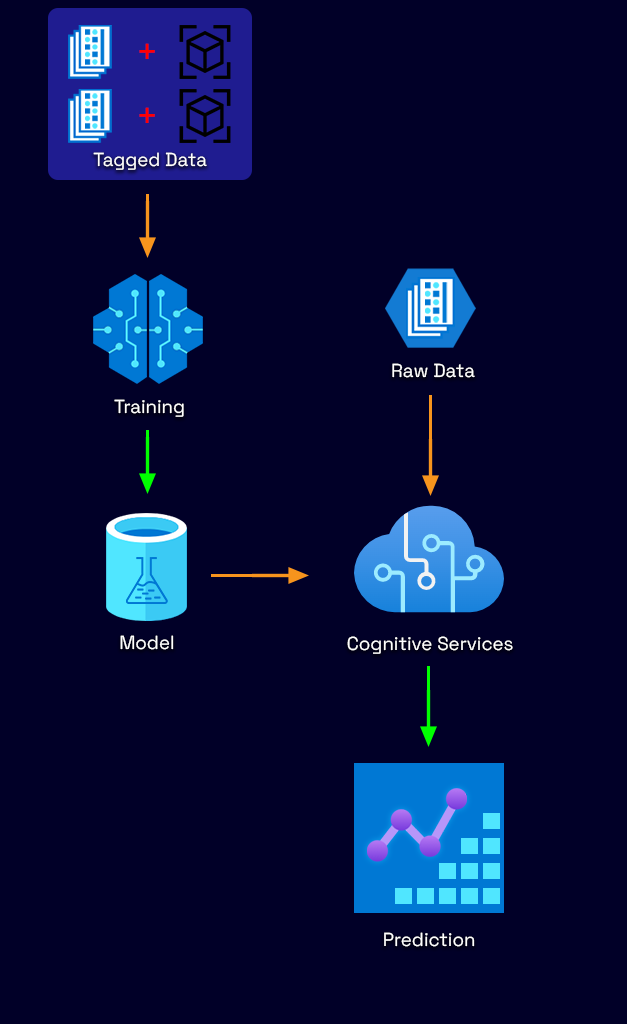
To tackle any challenge such as object detection with ML there is a process that must be followed which can be split into two parts. We’ll explain the process then guide you through how to perform this in Custom Vision.
Part One – Training a predictive model
The first part of the process involves training a machine on some input data. In our case this input data will be images. We will specify where in each image there is a license plate, this is referred to as ‘tagging’ or ‘labelling’. It is beneficial to include a variety of different lighting conditions, environments, and angles. We’ll later go into detail on how to improve this model to be more accurate.

The tagged images will then be run through the ML training process and the output will make up the ‘model’ which we will use in the next step to run predications on new unseen data.

Part Two – Running Predictions
The second part of the process involves using the model created from the first to run predictions on new unseen data. In our case it will be new images of cars with license plates visible in them. We will not tag these images but observe to see if there are accurate predictions after they have been run through the service.
Step-By-Step On Getting Started With Custom Vision
Custom Vision is an image recognition service provided by Azure to build and deploy your own image identification model. It lets you perform the process described above by uploading your own images and tagging them with labels depending on the outcome you wish to see. Custom Vision will then train on this data using machine learning algorithms to calculate its own accuracy by testing itself on the same set of images. You can then test and retrain the model as much as you wish to ultimately use it within your own application.
The service facilitates two features.
- Image classification
- Applies labels and classifies images based upon those labels. An example would be if you were distinguishing different types of fruit.
- Object detection
- Detects objects within an image and the output results contain coordinates of their location.
Object detection is what we will utilize it for and see how the accuracy of our model can be improved by iterations.
Setting up a new Project
To use Custom Vision you must have a Microsoft account linked to an Azure subscription. Head over to the website at https://customvision.ai/ and click on Sign-In.
Once you are signed in you can go ahead and create a new project.
This action should bring up a dialog modal which requests some basic information about the project.
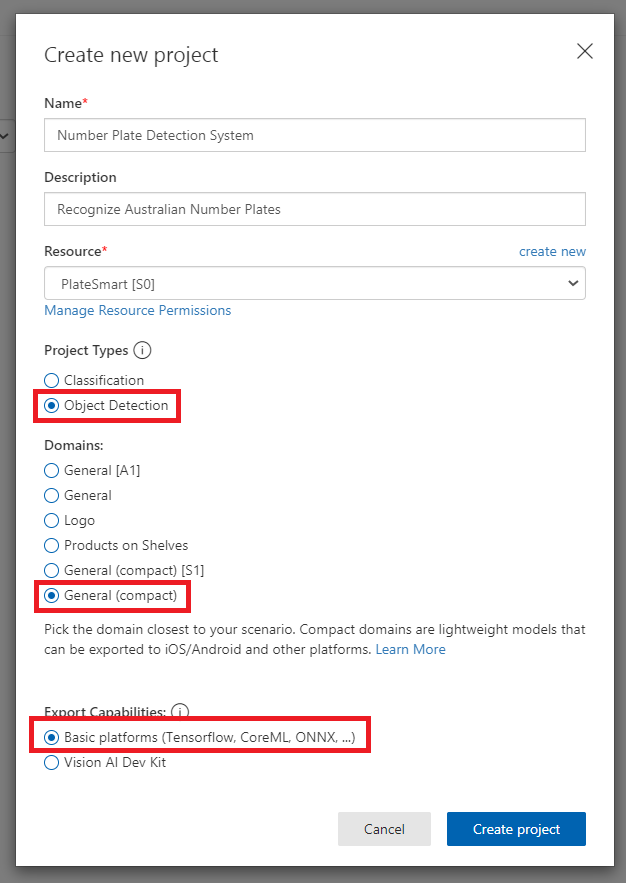
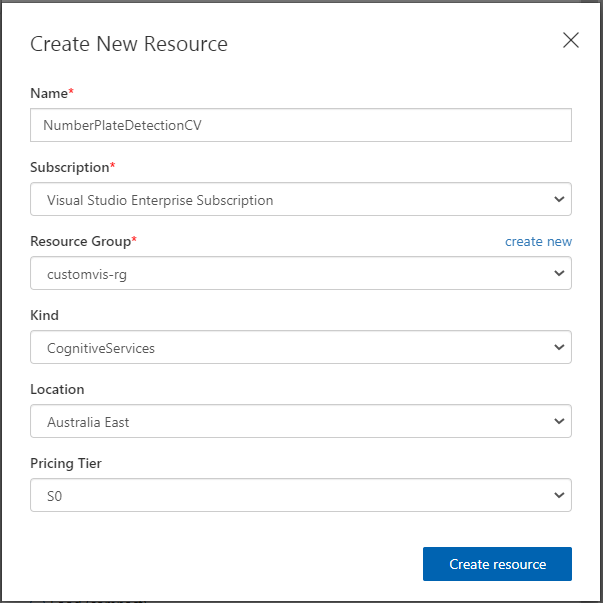
You can then go ahead and fill in the Name and Description to what you would like. For the Resource field you may need to press ‘create new’ and fill in additional information to create a resource for this project. Make sure the Project type is set to ‘Object Detection’ since we are detecting objects for this demonstration. The Domains option you can leave as General however, I strongly recommend setting this to General (compact) as this gives you the ability to export your model at a later stage. It can then be used offline.
Training for Object Detection
Once the project has been created you are presented with the main interface of Custom Vision you will be using throughout this demo. On the top navigation bar, we have “Training Images”, “Performance” and “Predictions”.
Preparing and tagging input data
Training Images is where we begin to upload images to start training the system into detecting the objects we want. Since there are no images, we can press the Add images button and upload some photos of cars. Microsoft recommends at least 30 images per tag to create something tangible to work with. I would recommend collecting a whole variety of images of cars and license plates.
If you lack data to use you can simply google for example “cars with NSW license plates” to find images to use. Alternatively, I’ve found that websites that allow individuals to sell their cars have adequate photos you can potentially use. If all else fails, go out and take some of your own photos!
The next step is to tag the images uploaded, you will see they show up under the untagged filter and clicking on one will bring up the image in full.
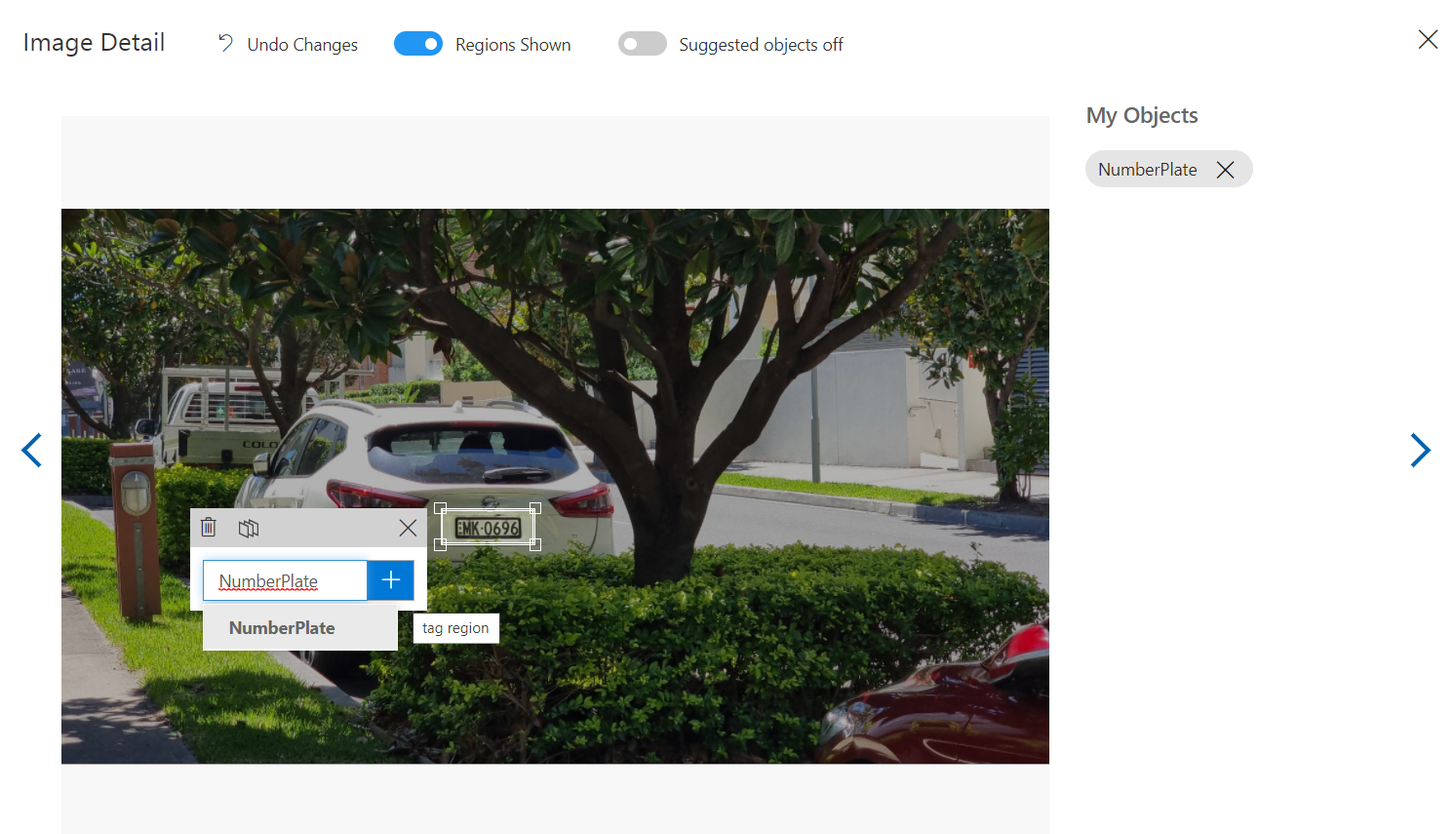
Custom Vision tries to guess and suggest several objects in the picture as a dotted box outline which you can click to help you tag elements faster. You can also manually specify the region yourself by clicking and dragging to set up a new tag.
Once you have gone through and tagged your images you can see now, they are filtered as ‘Tagged’ along with a summary of how many tags were used.
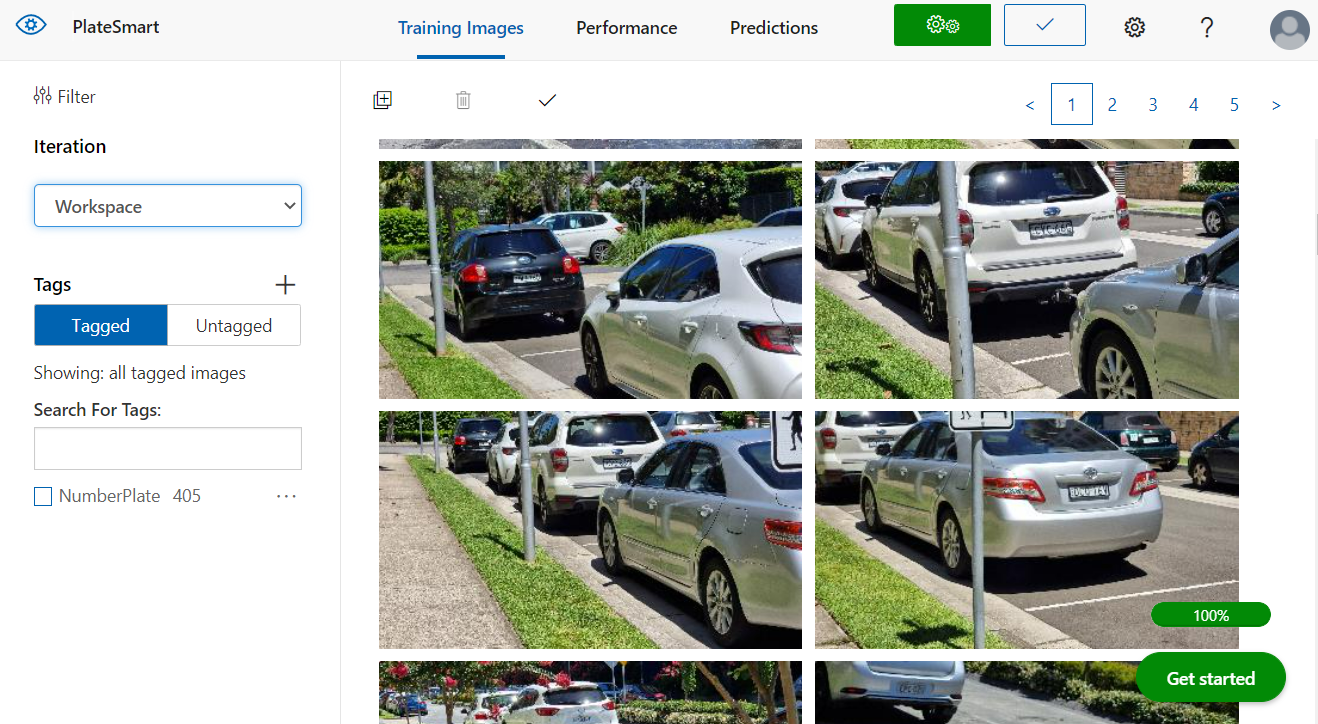
Training
The next step is training the system! You can do this by pressing on the green train button with the cogs. It will popup with a dialog modal asking you to select the training type. Since this is our first iteration you may go ahead and choose Quick Training and hit Train.
At a later stage when you add more images you can perform the advanced training option which asks you to set a budget of time. It also gives you a nice option to be notified via email when the training is complete.
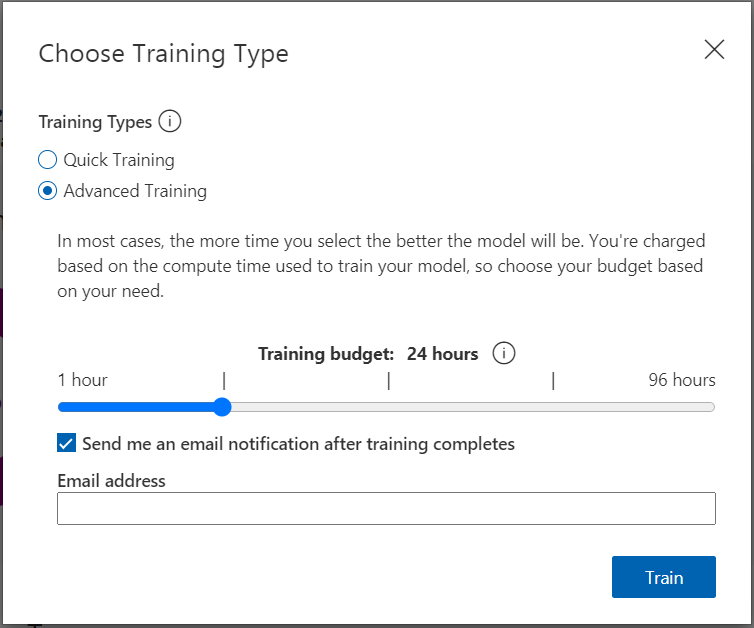
Since you have chosen the quick training option you can go get a coffee and come back to check periodically if it has completed.
Training Results & Outcome
Once the training is complete you can see the statistical results of your first iteration. Let’s run you through what each of these mean:

- Precision. This represents the accuracy of predictions by the model, for example if the predictive model identified 100 images of number plates which was run through it but only 91 of them were actual images of number plates then the accuracy would be 91%.
- Recall means out of the tags which should be predicted correctly, what percentage did your model correctly find? A similar example if there were 100 images of number plates but only 56 were identified by the model then the recall would be 56%.
- mAP (Mean average precision) means the overall object detector performance across all the tags. So, if you had more than one what the average precision would be.
On the Performance Tab there are also two sliders, “Probability Threshold” and “Overlap Threshold”. These can be used to fine tune how you want the model to behave. The probability threshold represents the level of confidence a prediction needs to be deemed valid. If you don’t mind false positive results adjusting this can cause the recall value to increase while decreasing the precision meaning the images run through the prediction will have more objects detected.
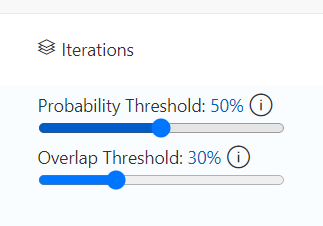
Testing
Now we can go ahead and test the model quickly to see how it performs. On the main page if you hit the ‘Quick Test’ button next to where it had Train it will bring up a window that lets you upload an image to run through the model.
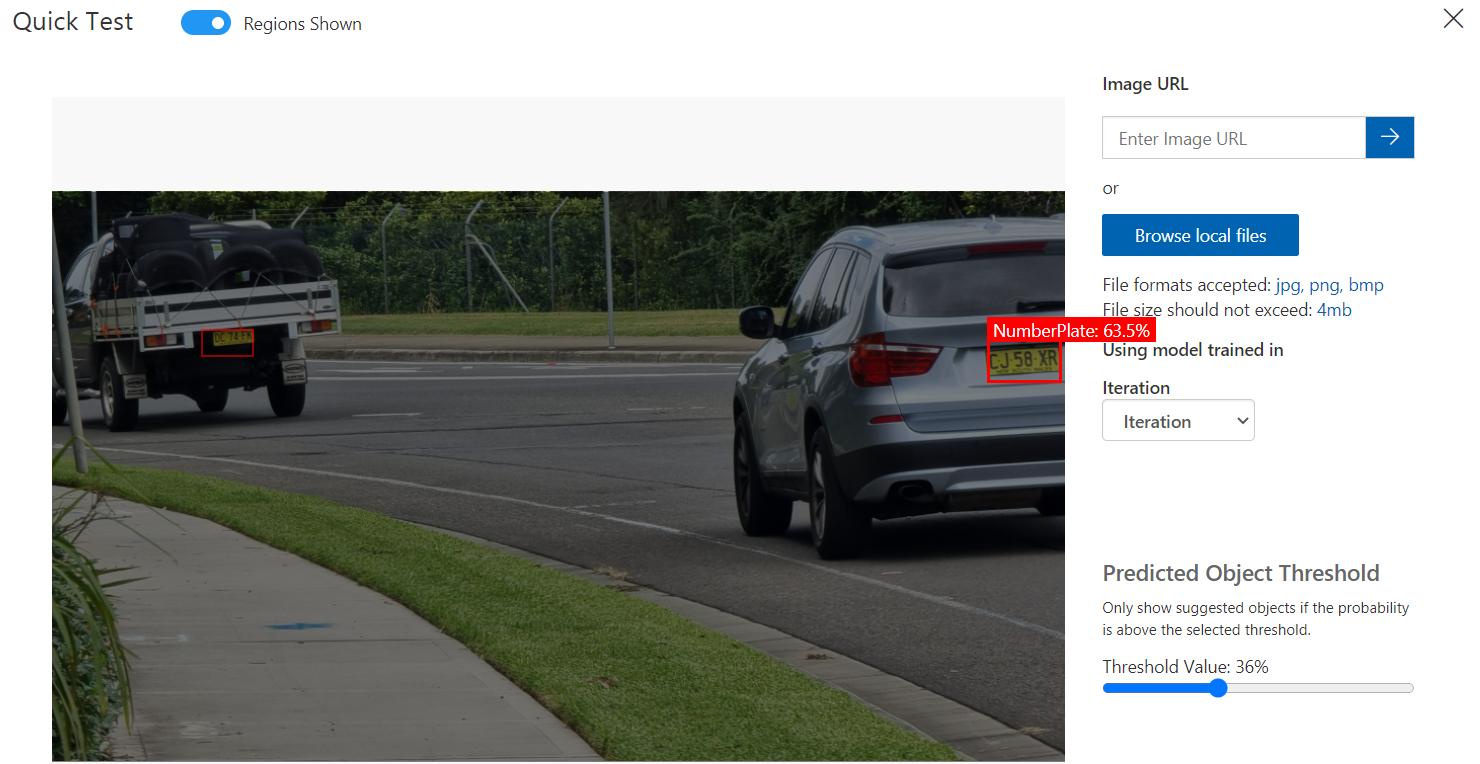
In this example we’ve uploaded an image containing two vehicles. You can see it has identified the number plates on both indicated by the red box. The confidence or probability percentage is also highlighted, the car on the right’s number plate has a probability of 63.5%.
There is also a useful slider there which lets you adjust the threshold filter so you can see what it predicted and the confidence it had when making those predictions at a certain level.
Publishing and putting this to use
Now that we have a working model Custom Vision gives us the ability to publish this on Azure into a resource service with an API. This will let us query images and get back predictions programmatically.
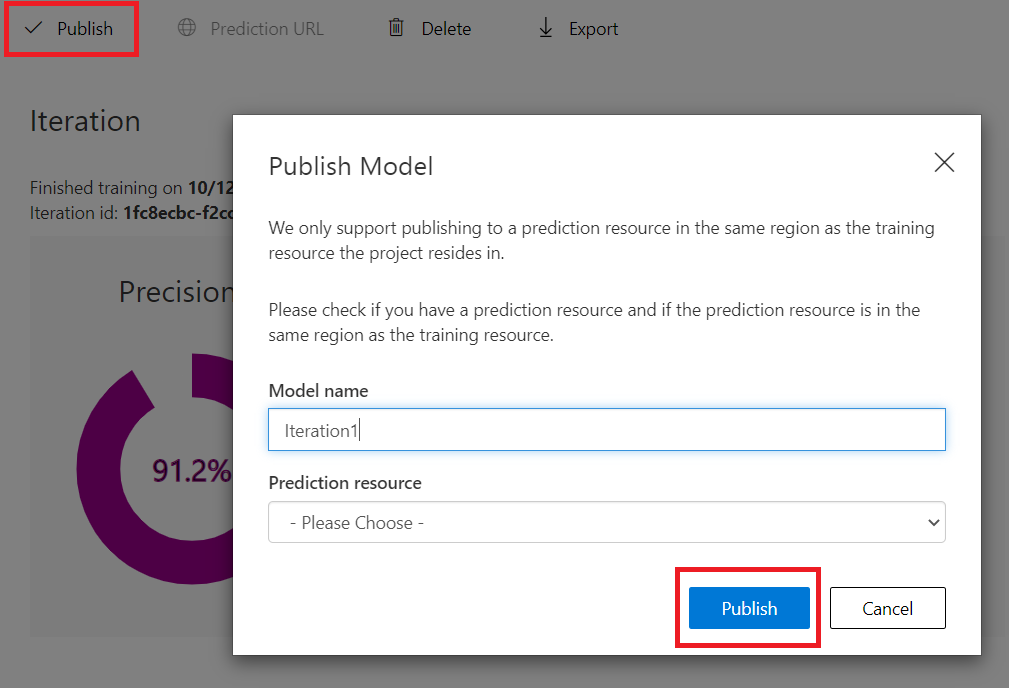
On the Performance Tab on the selected Iteration if you press on the Publish button it will present a window that lets you select to which resource you want to deploy this model and asks you for a name.
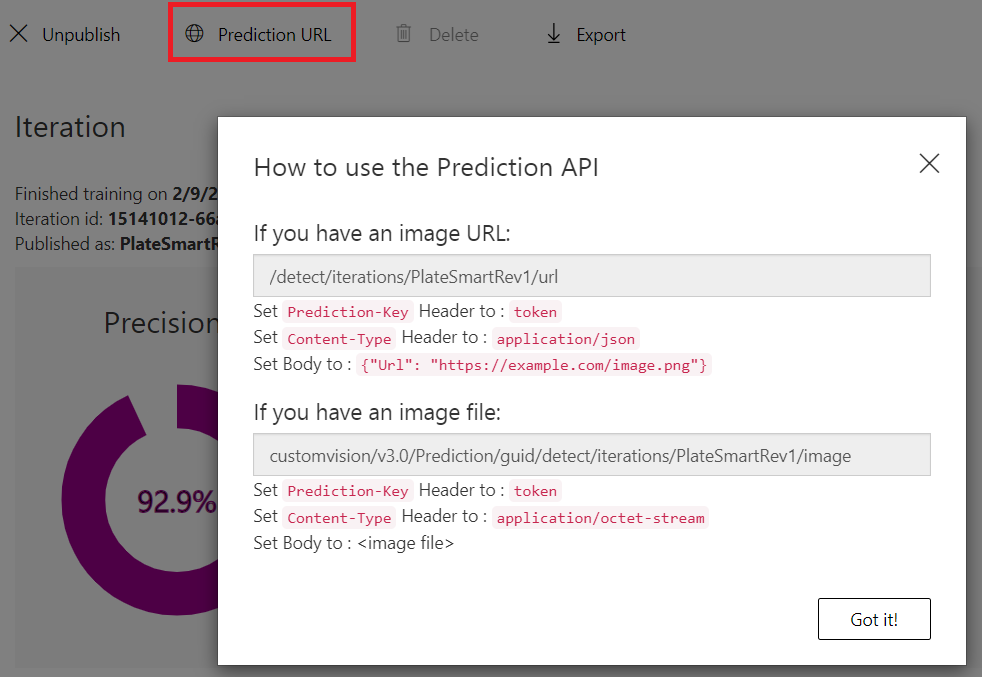
Once you have published the model you can access the prediction API URL. This gives you some information on how to call the API and pass in the required relevant data.
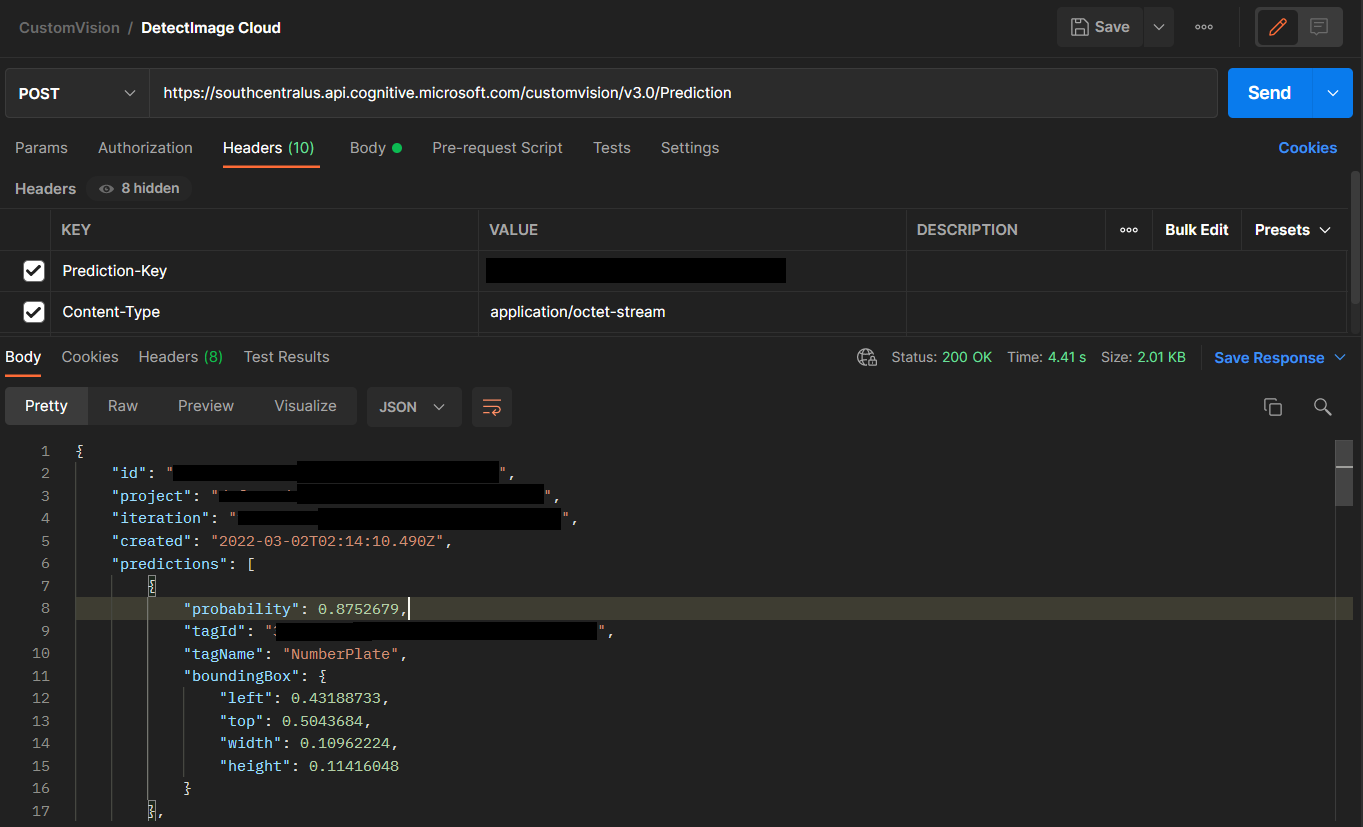
You can try these APIs with Postman and observe the response returned. A JSON object with an array of predictions that contain the probability, the tag id, tag name and the bounding box region of the detected object relative to the image are received.
Improving your model
Improving your model comes down to two things. Adding more good quality data and re-training. The last navigation menu option “Predictions” on Custom Vision shows you the images you have uploaded to test your model for a given iteration.
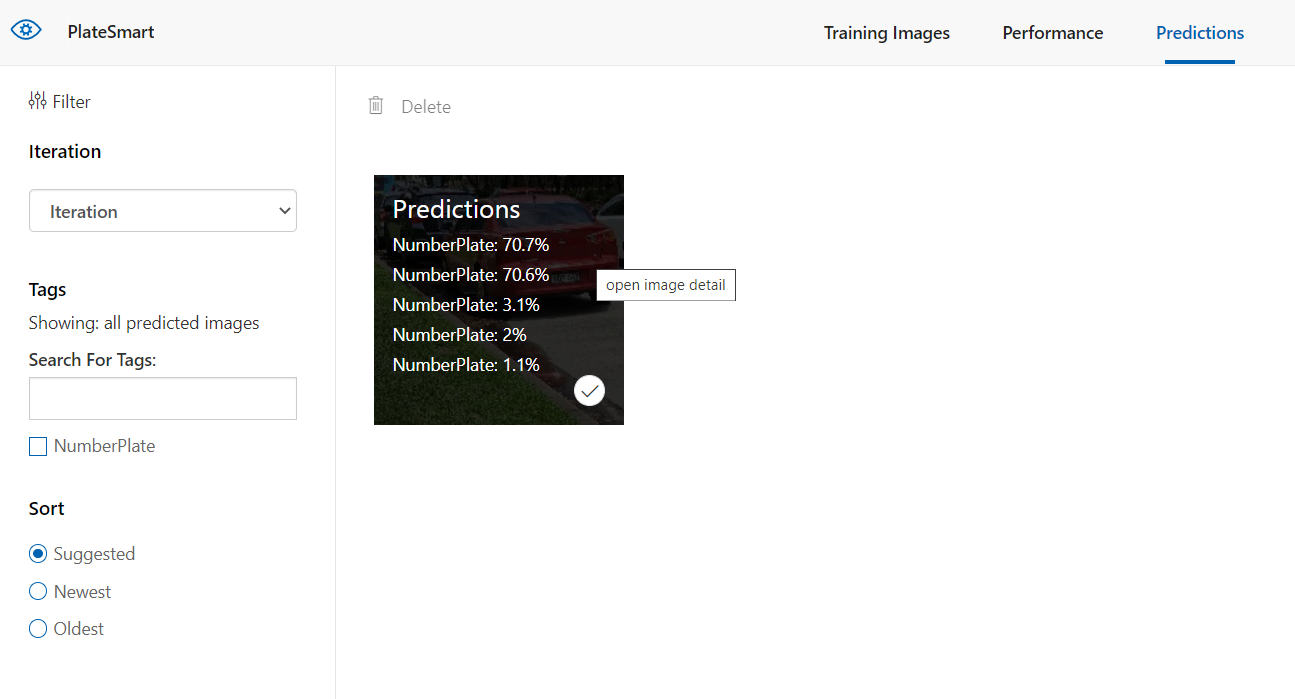
Clicking on each image here lets you adjust and remove wrong predictions made. In our case, sometimes the system would detect the body frame of the vehicle in the photo as a number plate, so we’d have to go into the image and redraw the region the number plate resided in.

You can see in this image the detected region is cropping the number plate characters so we had to adjust the size to cover the full area of the plate. Once you have done this process for a few images you can go ahead and train the model again creating a new iteration.
Data variety and quality
To improve the accuracy and quality of your model you need to provide it with a good variety of data. With the demo example of the number plates, we’d decided to only use dashcam footage screenshots of vehicles with their plates visible, but we slowly realised we were training the model to detect not number plates, but the rear bumper components of the vehicles in the shot. That only changed when we uploaded a variety of photos of number plates not attached to cars.
The official documentation explains this in greater detail under the section: “How to improve your Custom Vision Model”.
Speed and Practicality
Let’s discuss the topic of speed with this service. You may be concerned with the latency impact of making API calls to Custom Vision, or issues requiring you to be connected to the Internet. These concerns are all ones we’ve faced before using a Cloud Computing platform, however with Custom Vision it gives you the ability to export your model to a variety of platforms allowing it to run in an offline environment.
Exporting your model
You can check this feature out by going to the Performance tab on Custom Vision and hitting the Export button on the iteration you desire.
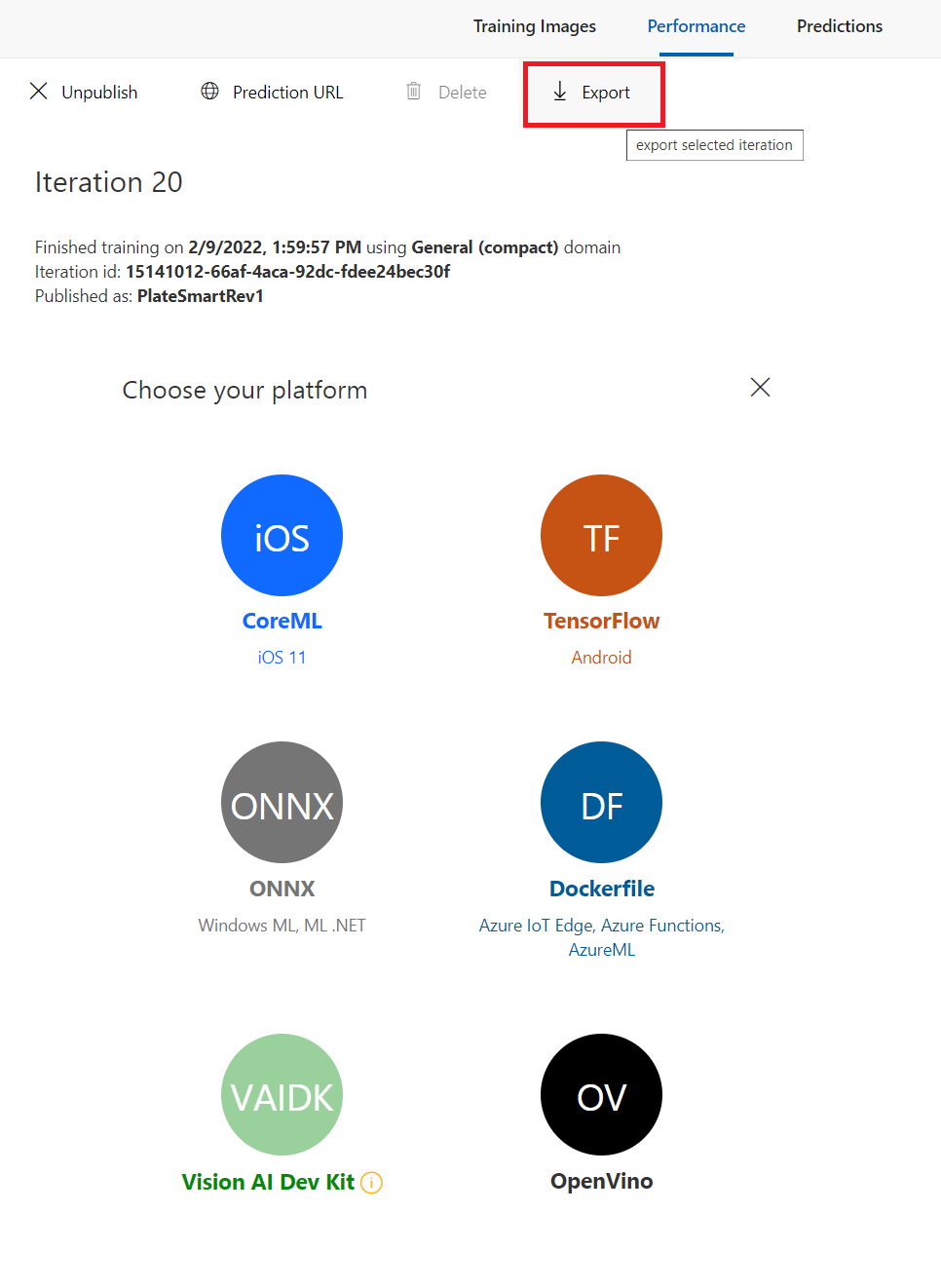
You can see on this screen we are presented with many different export options. To demonstrate the proof of concept we will go with the docker container image option. Select Dockerfile and on the popup modal set the export platform to Linux then hit Export. This will take a moment then present you with a Download button. Download the image zip file and extract to a new directory on your local machine. For more information on Docker and how Docker images work check out the getting started guide on the Docker website.
Deploying our Custom Vision Image Service on Docker

Once you have downloaded the docker image zip you can clone the demo project from my GitHub.
https://github.com/cihansol/CustomVision.
I’ve made it easy to setup the service using a simple PowerShell script. It will unpack, build and deploy it in your local environment. Make sure you have Docker installed along with the WSL 2 backend.
- Make sure Docker is running and it’s in your PATH Environment Variable.
- Export your own model docker image from Custom Vision or use the provided demo model and put it into the \Docker directory.
- Either drag and drop the .zip package onto the DragNDropRunWindows.bat or open a PowerShell window in the \Docker directory and type: ExtractBuildRun.ps1 1514101266af4aca92dcfdee24bec30f.DockerFile.Linux.zip where 1514101266af4aca92dcfdee24bec30f.DockerFile.Linux.zip is the name of the model package file.
- After it builds and runs it will display * Running on http://172.17.0.2:80/ (Press CTRL+C to quit). This will be the internal address the server is running at, it can be accessed locally at http://127.0.0.1/image
- To terminate the service in the console window press CTRL+C
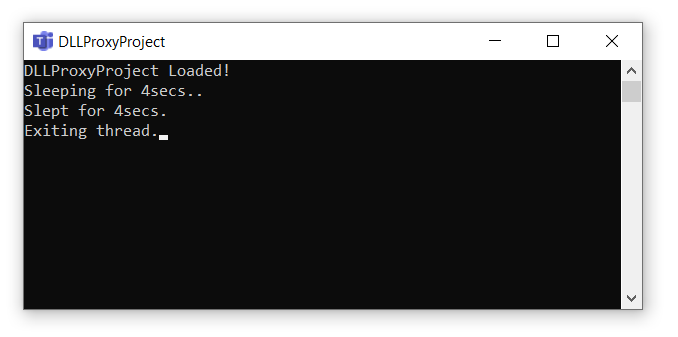
Building and running the demo will present an output like below. It will consume the images inside the samples directory and run them through the custom vision service you have running locally on Docker.
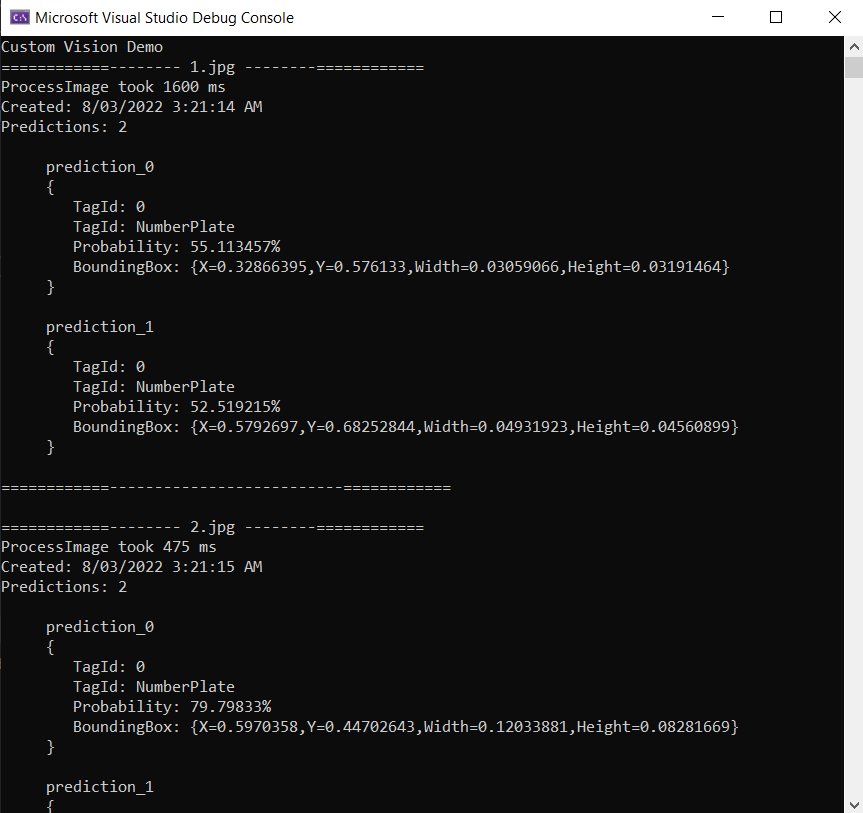
Conclusion
Machine learning’s success stems from the quality and variety of data that is processed. We’ve demonstrated how easy it is to build your own machine learning prediction model with the Azure Custom Vision service. We’ve gone through the detailed process involved with tagging input data along with iterating and improving the accuracy of the model. In the next blog post we’ll discuss how to apply object detection to real time video and the challenges and solutions to that problem.




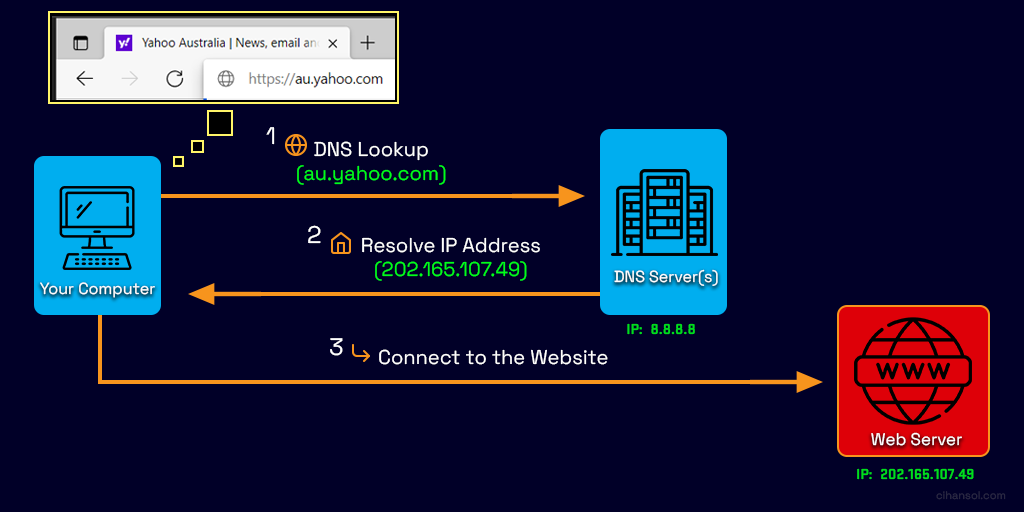
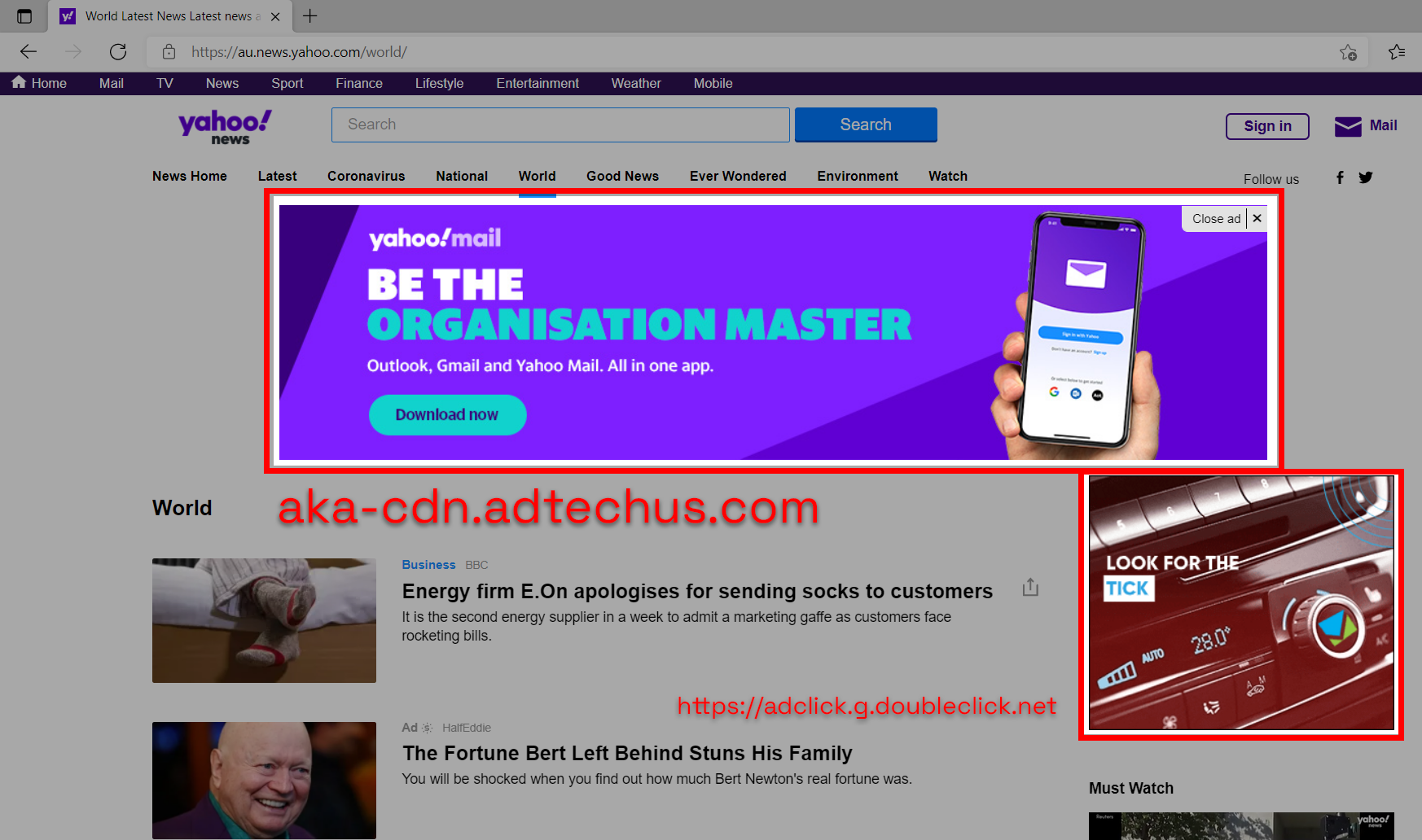
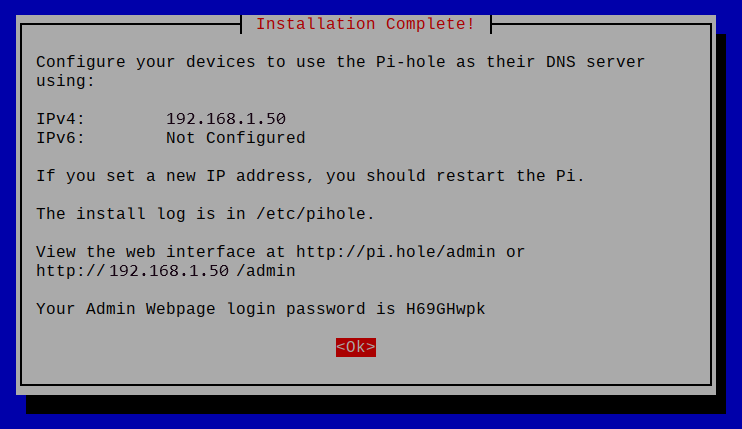
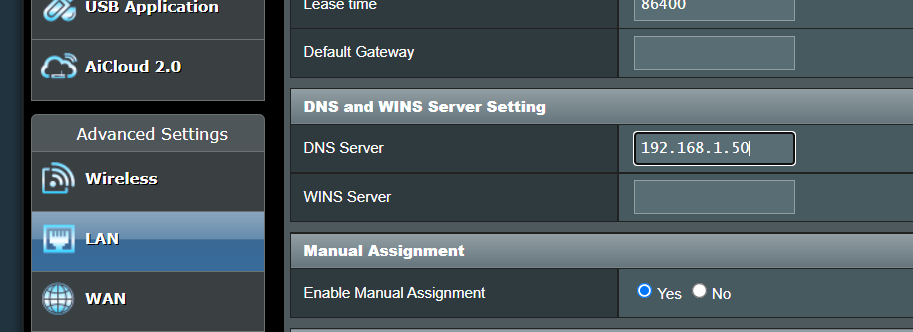
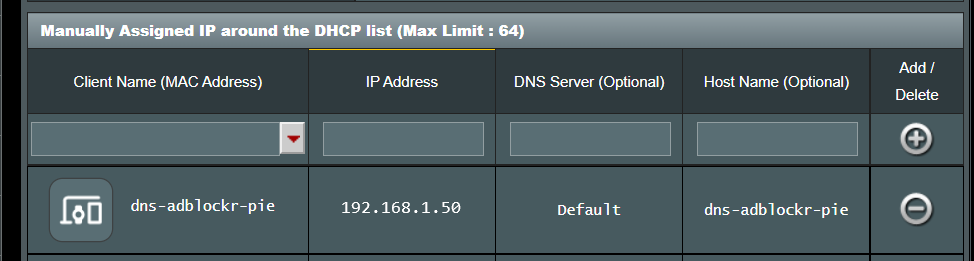
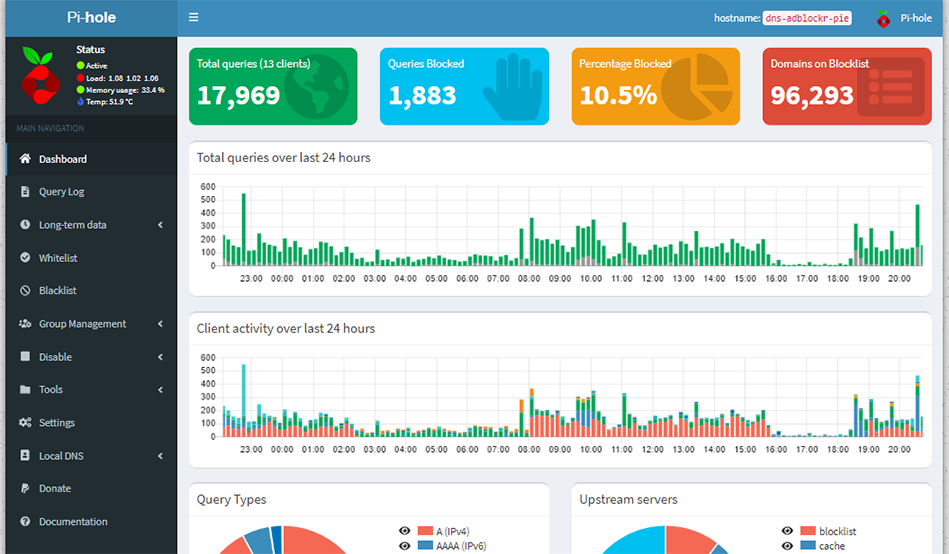
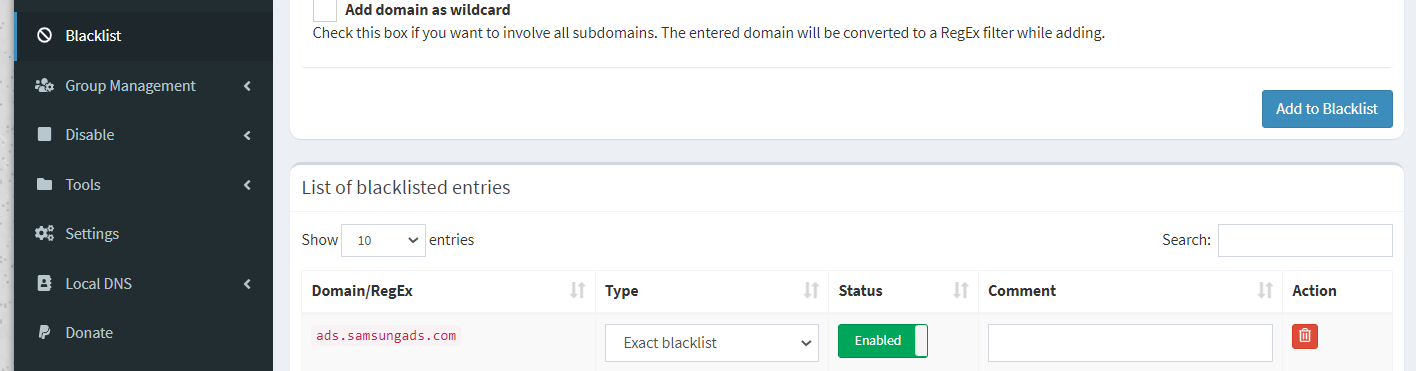
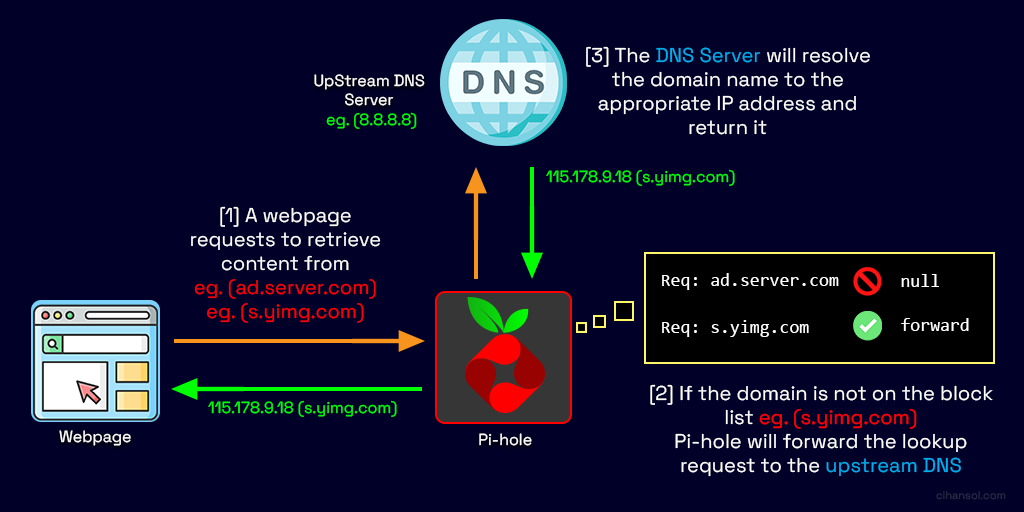 Using Pi-hole we can also effectively control domain access on our networks creating our own blacklist for websites that may be malicious or dangerous and this can also assist in filtering out adult content for the young ones or employees in your home or office network.
Using Pi-hole we can also effectively control domain access on our networks creating our own blacklist for websites that may be malicious or dangerous and this can also assist in filtering out adult content for the young ones or employees in your home or office network.